Lecture 3: Optimal Policy and Bellman Optimality Equation
1-Outline
In this lecture:
- Core concepts: optimal policy and optimal state value
- A fundamental tool: Bellman optimality equation (BOE)
2-Motivating examples

vπ(s1)=−1+γvπ(s2),
vπ(s2)=+1+γvπ(s4),
vπ(s3)=+1+γvπ(s4),
vπ(s4)=+1+γvπ(s4).
-
State values: vπ(s4)=vπ(s3)=vπ(s2)=10,vπ(s1)=8
-
Exercise: calculate the action values of the five actions for s1
-
Action values:
qπ(s1,a1)=−1+γvπ(s1)=6.2,
qπ(s1,a2)=−1+γvπ(s2)=8,
qπ(s1,a3)=0+γvπ(s3)=9,
qπ(s1,a4)=−1+γvπ(s1)=6.2,
qπ(s1,a5)=0+γvπ(s1)=7.2.
- Question: While the policy is not good, how can we improve it?
- Answer: We can improve the policy based on action values.
In particular, the current policy π(a∣s1) is:
π(a∣s1)={10a=a2a=a2
Observe the action values that we obtained just now:
qπ(s1,a1)=6.2,qπ(s1,a2)=8,qπ(s1,a3)=9,
qπ(s1,a4)=6.2,qπ(s1,a5)=7.2.
What if we select the greatest action value? Then, the new policy is
πnew(a∣s1)={10a=a3a=a3
- Question: Why doing this can improve the policy?
- Intuition: Action values can be used to evaluate actions.
- Math: nontrivial and will be introduced in the this lecture.
3-Definition of optimal policy
The state value could be used to evaluate if a policy is good or not: if
vπ1(s)≥vπ2(s)for alls∈S
then π1 is “better” than π2.
- Definition: A policy π∗ is optimal if vπ∗(s)≥vπ(s) for all s and for any other policy π.
The definition leads to many questions:
- Does the optimal policy exist?
- Is the optimal policy unique?
- Is the optimal policy stochastic or deterministic?
- How to obtain the optimal policy?
To answer these questions, we study the Bellman optimality equation.
4-BOE: Introduction
- Bellman optimality equation (elementwise form):
v(s)=πmaxa∑π(a∣s)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)v(s′)),s∈S
=πmaxa∑π(a∣s)q(s,a),s∈S
v=πmax(rπ+γPπv)
where the elements corresponding to s or s′ are
[rπ]s≜a∑π(a∣s)r∑p(r∣s,a)r,
[Pπ]s,s′=p(s′∣s)≜a∑π(a∣s)s′∑p(s′∣s,a)
Here maxπ is performed elementwise:
πmax⎣⎢⎢⎡∗⋮∗⎦⎥⎥⎤=⎣⎢⎢⎡maxπ(s1)∗⋮maxπ(sn)∗⎦⎥⎥⎤
- Remarks:
- BOE is tricky yet elegant!
- Why elegant? It describes the optimal policy and optimal state value in an elegant way.
- Why tricky? There is a maximization on the right-hand side, which may not be straightforward to see how to compute.
- This lecture will answer all the following questions:
- Algorithm: how to solve this equation?
- Existence: does this equation have solutions?
- Uniqueness: is the solution to this equation unique?
- Optimality: how is it related to optimal policy?
5-BOE: Preliminaries
5.1-BOE: Maximization on the right-hand side
5.2-BOE: Rewrite as v=f(v)
The BOE is v=maxπ(rπ+γPπv). Let
f(v):=πmax(rπ+γPπv)
Then, the Bellman optimality equation becomes
v=f(v)
where
[f(v)]s=πmaxa∑π(a∣s)q(s,a),s∈S
This equation looks very simple. How to solve it?
5.3-Contraction mapping theorem(压缩映射定理)
Some concepts:
- Fixed point: x∈X is a fixed point of f:X→X if
f(x)=x
- Contraction mapping: f:X→X is a contraction mapping if
∣∣f(x1)−f(x2)∣∣≤γ∣∣x1−x2∣∣
where γ∈(0,1).
- Remarks:
- γ must be strictly less than 1 so that many limits such as γk→0 as k→∞ hold.
- Here ∣∣⋅∣∣ is the norm of the vector space X.
Examples to demonstrate the concepts:
Above all, we can get the definition of Contraction Mapping Theorem:
6-BOE: Solution
6.1-Contraction property of BOE
Let’s come back to the Bellman optimality equation:
v=f(v)=πmax(rπ+γPπv)
6.2-Solve the Bellman optimality equation
Applying the contraction mapping theorem gives the following results:
Importance:The algorithm in (1) is called the value iteration algorithm.
7-Optimality
7.1-Policy Optimality
Suppose v∗ is the solution to the Bellman optimality equation. It satisfies
v∗=πmax(rπ+γPπv∗)
Suppose
π∗=argπmax(rπ+γPπv∗)
Then
v∗=rπ∗+γPπ∗v∗
Therefore, π∗ is a policy and v∗=vπ∗ is the corresponding state value.
Is π∗ the optimal policy? Is v∗ the greatest state value can be achieved?
Now we understand why we study the BOE. That is because it describes the optimal state value and optimal policy in an elegant way.
7.2-Optimal policy
What does an optimal policy π∗ look like?
π∗(s)=argπmaxa∑π(a∣s)q∗(s,a)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)v∗(s′))
8-Analyzing optimal policies
What factors determine the optimal state value and optimal policy?
It can be clearly seen from the BOE
v(s)=πmaxa∑π(a∣s)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)v(s′))
that there are three factors:
- System model: p(s′∣s,a), p(r∣s,a)
- Reward design: r
- Discount rate: γ
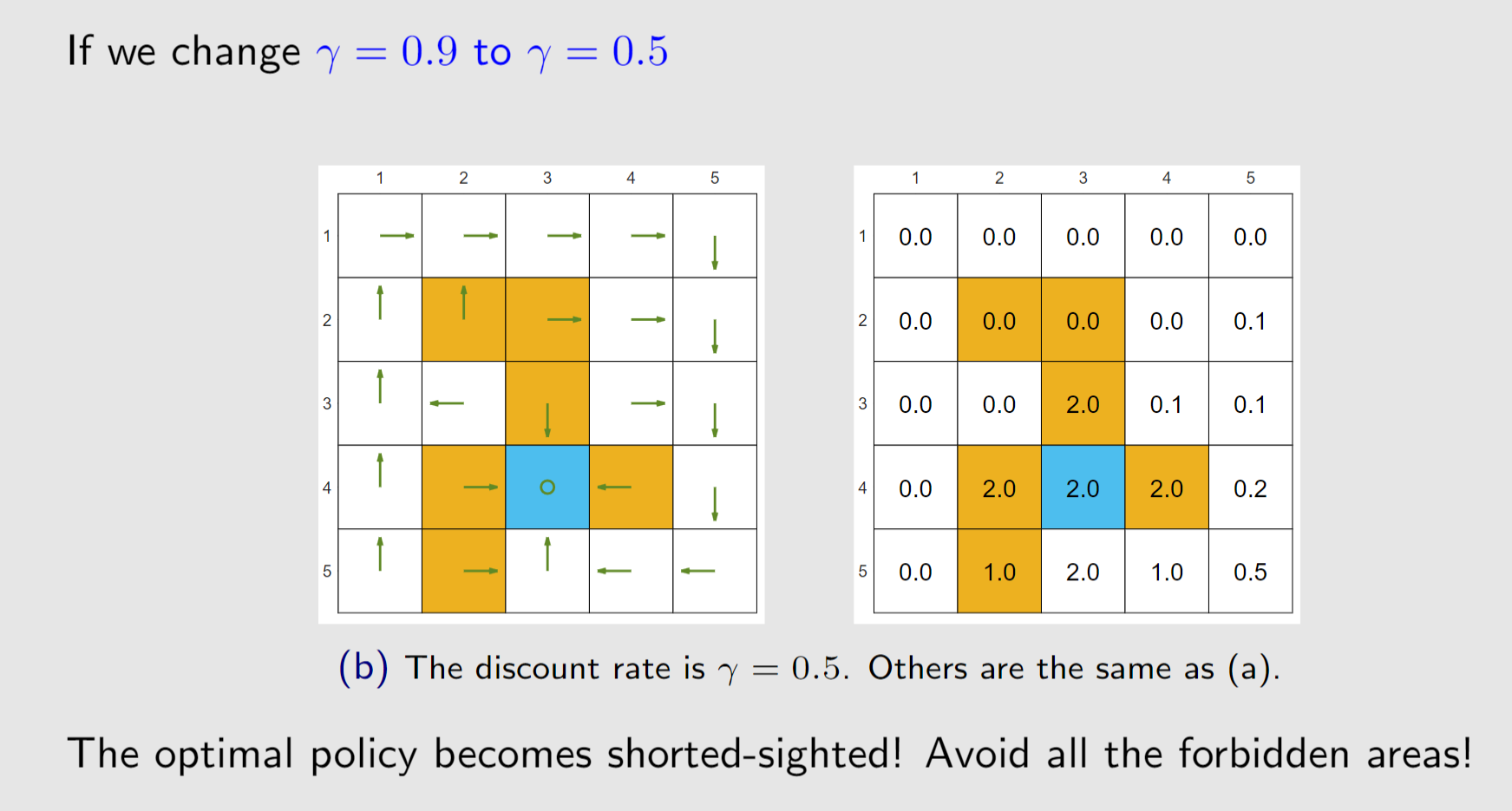
We next show how r and γ can affect the optimal policy.
9-Additional Content
9.1-压缩映射定理的详细解读
-
存在性(Existence):必有一个不动点 x∗
- “there exists a fixed point x∗ satisfying f(x∗)=x∗”
- 含义:只要 f 是“完备度量空间上的压缩映射”,就一定存在至少一个 x∗,使得 f(x∗)=x∗(即不动点方程有解)。
- 为什么存在?(结合文献3、4的证明思路):
- 从空间中任意选一个初始点 x0,构造迭代序列:x1=f(x0),x2=f(x1)=f(f(x0)),x3=f(x2)=f(f(f(x0)))…
- 因为 f 是压缩映射,这个序列是“柯西序列”(序列中越靠后的点,彼此距离越近,趋近于0);而空间是完备的,柯西序列一定收敛到某个极限 x∗,这个 x∗ 就是不动点(对 xk+1=f(xk) 两边取极限,得 x∗=f(x∗))。
-
唯一性(Uniqueness):不动点 x∗ 是唯一的
- “The fixed point x∗ is unique”
- 含义:不存在第二个不动点 y∗(即不动点方程只有一个解)。
- 怎么证明唯一?(反证法,文献3、4通用):
- 假设还有另一个不动点 y∗(满足 f(y∗)=y∗),则:d(x∗,y∗)=d(f(x∗),f(y∗))≤α⋅d(x∗,y∗)
- 因为 α<1,两边同时减去 α⋅d(x∗,y∗),得:d(x∗,y∗)−α⋅d(x∗,y∗)≤0⟹d(x∗,y∗)⋅(1−α)≤0
- 又因为 1−α>0,所以只能是 d(x∗,y∗)=0,即 x∗=y∗,因此不动点唯一。
-
算法(Algorithm):迭代序列收敛到 x∗,且指数收敛
-
“Consider a sequence {xk} where xk+1=f(xk), then xk→x∗ as k→∞. Moreover, the convergence rate is exponentially fast.”
-
含义:给了一个具体的求解方法——从任意初始点 x0 出发,用 xk+1=f(xk) 迭代生成序列,当迭代次数 k 足够大时,xk 会无限趋近于不动点 x∗,且收敛速度是“指数级”的(很快)。
-
直观例子(以 f(x)=0.5x 为例):
取初始点 x0=1,则:
x1=f(x0)=0.5×1=0.5
x2=f(x1)=0.5×0.5=0.25
x3=f(x2)=0.5×0.25=0.125
x4=0.0625,…,xk=(0.5)k
当 k→∞ 时,xk→0(即不动点 x∗=0)。
-
指数收敛的意义:
- 误差 d(xk,x∗) 会按 αk 的速度缩小(α<1)。比如 α=0.5,迭代10次后,误差就是初始误差的 (0.5)10≈10241,迭代20次后误差约 1061,很快就能逼近不动点,这也是压缩映射定理在数值计算中(比如解微分方程、强化学习贝尔曼方程)被广泛应用的原因——迭代高效。
9.2-证明BOE是压缩映射
- 压缩映射的定义回顾
在度量空间(此处为“有界价值函数空间 + 合适的范数,如无穷范数 ∥⋅∥∞”)中,若映射 f:X→X 满足:存在常数 α∈[0,1),使得对任意 v1,v2∈X,有
∥f(v1)−f(v2)∥≤α∥v1−v2∥
则 f 是压缩映射(α 为“压缩常数”,需小于1)。
- 分析贝尔曼最优方程的映射结构
BOE的映射形式为:
f(v)=πmax(rπ+γPπv)
其中:
- rπ:策略 π 下的期望即时奖励向量(每个元素对应一个状态的期望奖励)。
- Pπ:策略 π 下的状态转移概率矩阵(每行元素和为1,因为是概率转移)。
- γ:折扣因子,满足 0≤γ<1。
- 关键步骤:证明范数的“压缩性”
需证明:对任意两个价值函数 v1,v2,有
∥f(v1)−f(v2)∥≤γ∥v1−v2∥
- 步骤1:分析“单策略下的转移项”
对任意一个策略 π,考虑 rπ+γPπv 对 v 的依赖:
(rπ+γPπv1)−(rπ+γPπv2)=γPπ(v1−v2)
由于 Pπ 是转移概率矩阵(每行元素和为1,元素非负),根据“矩阵与向量乘法的范数性质”:
对无穷范数 ∥⋅∥∞,有 ∥Pπw∥∞≤∥w∥∞(加权平均不会放大向量的无穷范数)。
因此:
∥(rπ+γPπv1)−(rπ+γPπv2)∥∞=γ∥Pπ(v1−v2)∥∞≤γ∥v1−v2∥∞
- 步骤2:对“所有策略取最大值”的影响
f(v) 是对所有策略 π 逐元素取最大值的结果(即每个状态的价值,取所有策略下 rπ+γPπv 的最大值)。
根据“最大值运算的单调性”:若 g1(π)≤g2(π)+c 对所有 π 成立,则 maxπg1(π)≤maxπg2(π)+c。
令 g1(π)=rπ+γPπv1,g2(π)=rπ+γPπv2,则 g1(π)−g2(π)≤γ∥v1−v2∥∞(由步骤1)。因此:
πmaxg1(π)−πmaxg2(π)≤πmax(g1(π)−g2(π))≤γ∥v1−v2∥∞
这意味着:
∥f(v1)−f(v2)∥∞≤γ∥v1−v2∥∞
- 结论:满足压缩映射的条件
由于折扣因子 γ∈[0,1)(压缩常数小于1),因此映射 f(v)=maxπ(rπ+γPπv) 是压缩映射。