The Mathematical Principles of Reinforcement Learning

The Mathematical Principles of Reinforcement Learning
Penry引言
本笔记系统整理和总结了强化学习领域的核心数学原理,内容主要参考自B站课程:【强化学习的数学原理】课程:从零开始到透彻理解(完结)。课程由西湖大学工学院赵世钰老师主讲,涵盖了强化学习的基本概念、马尔可夫决策过程(MDP)、动态规划、蒙特卡洛方法等重要内容,本课程重点讲解的是 RL 的算法原理,适合希望深入理解强化学习本质的同学学习。赵老师的个人主页可参考:赵世钰。
相关资源与链接整理如下:
- 课程视频(知乎):https://www.zhihu.com/education/video-course/1574007679344930816?section_id=1574047391564390400
- 课程视频(B站):https://space.bilibili.com/2044042934
- 全英课程视频(YouTube):https://www.youtube.com/watch?v=ZHMWHr9811U&list=PLEhdbSEZZbDaFWPX4gehhwB9vJZJ1DNm8&index=2
- 书籍PDF与PPT下载(GitHub):https://github.com/MathFoundationRL/Book-Mathmatical-Foundation-of-Reinforcement-Learning
- 课程介绍(知乎):https://zhuanlan.zhihu.com/p/583392915
- 西湖大学实验室网站:https://shiyuzhao.westlake.edu.cn/
说明:建议搭配豆包浏览器阅读,因为该课程笔记中大多数依托于PPT撰写,以及结合个人理解,英文较多,可以借助于豆包划词工具。
Overview of Reinforcement Learning in 30 Minutes
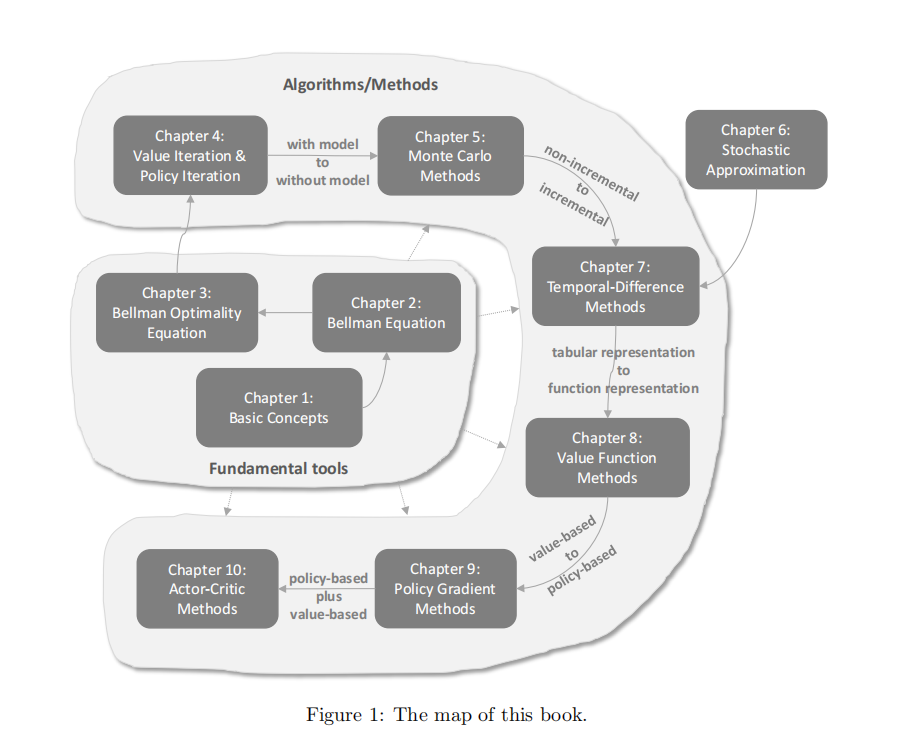
- Not just the map of this course, but also for RL fundations.
- Fundamental tools + Algorithms and methods.
- Importance of different parts.
- Chapter 1: Basic Concepts
- Concepts: state, action, reward, return, episode, policy,…
- Grid-world examples
- Markov decision process (MDP)
- Fundamental concepts, widely used later
- Chapter 2: Bellman Equations
- One concept: state value
- One tool: Bellman equation
- Policy evaluation, widely used later
- One concept: state value
- Chapter 3: Bellman Optimality Equations
- A special Bellman equation
- Two concepts: optimal policy and optimal state value
- One tool: Bellman optimality equation
- Fixed-point theorem (不动点原理)
- Fundamental problems
- 最优策略、最优的 state value是否存在
- 最优的 state value 是唯一的
- 最优的策略可能是 deterministic,也可能是 stochastic
- 一定存在确定性的最优策略
- An algorithm solving the equation
- Optimality, widely used later
- Chapter 4: Value Iteration & Policy Iteration
- First algorithms for optimal policies
- Three algorithms:
- Value iteration (VI) (值迭代)
- Policy iteration (PI) (策略迭代)
- Truncated policy iteration (截断策略迭代)
- Policy update and value update, widely used later
- Need the environment model
- Chapter 5: Monte Carlo Learning
- Gap: how to do model-free learning?
- Mean estimation with sampling data
- First model-free RL algorithms
- Algorithms:
- MC Basic (基本的 MC 算法)
- MC Exploring Starts (探索开始的 MC 算法)
- MC -greedy (基于 -贪婪的 MC 算法)
- Chapter 6: Stochastic Approximation
- Gap: from non-incremental to incremental
- Mean estimation
- Algorithms:
- Robbins-Monro (RM) algorithm ( Robbins-Monro 算法)
- Stochastic gradient descent (SGD) (随机梯度下降算法)
- SGD, BGD, MBGD
- Chapter 7: Temporal-Difference Learning
- Classic RL algorithms
- Algorithms:
- TD learning of state values (TD 学习状态值)
- SARSA: TD learning of action values (TD 学习动作值)
- Q-learning: TD learning of optimal action values (TD 学习最优动作值)
- On-policy & off-policy (基于策略与非基于策略)
- 强化学习中有两个策略:
- behavior policy,用于生成经验数据
- target policy,用于指导价值函数的更新
- 如果 behavior policy 与 target policy 相同,即 ,则称为 on-policy learning(基于策略学习)
- 如果 behavior policy 与 target policy 不同,即 ,则称为 off-policy learning(非基于策略学习)
- 强化学习中有两个策略:
- Unified point of view
- Chapter 8: Value Function Approximation
- Gap: tabular representation to function representation
- Algorithms:
- State value estimation with value function approximation (VFA) (状态值估计与价值函数近似):
- SARSA with VFA (Sarsa 算法与价值函数近似)
- Q-learning with VFA (Q-learning 算法与价值函数近似)
- Deep Q-learning
- State value estimation with value function approximation (VFA) (状态值估计与价值函数近似):
- Neural networks come into RL
- Chapter 9: Policy Gradient Methods
- Gap: from value-based to policy-based
- Contents:
- Metrics to define optimal policies:
- Policy gradient:
- Gradient-ascent algorithm (REINFORCE):
- Metrics to define optimal policies:
- Chapter 10: Actor-Critic Methods
- Gap: policy-based + value-based
- Algorithms:
- The simplest actor-critic (QAC)
- Advantage actor-critic (A2C)
- 引入了一个 baseline ,用于减少方差
- Off-policy actor-critic
- 使用 Importance sampling 的方法使得 QAC 由 on-policy 向 off-policy 转换
- Deterministic actor-critic (DPG)
- Gap: policy-based + value-based
Lecture 1: Basic Concepts in Reinforcement Learning
Contents
- First, introduce fundamental concepts in RL by examples.
- Second, formalize the conceptts in the context of Markov decision process.
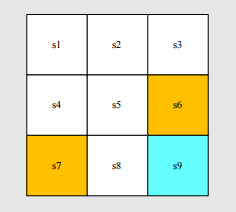
A grid-world example
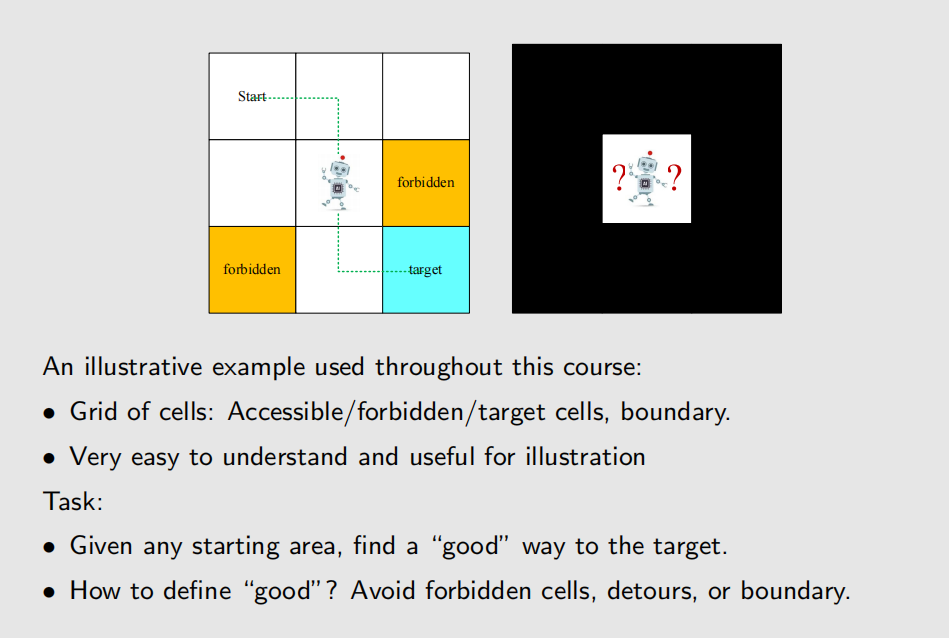
State
State: The status of the agent with respect to the environment
- 针对于 grid-world 示例,state 指的是 location,如下图中一共有 9 个 location,也就对应了 9 个 state。
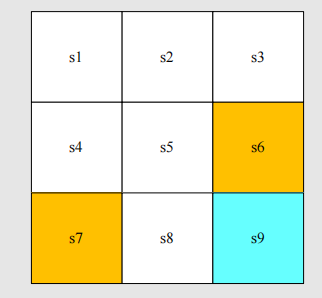
State space: The set of all states .
Action
Action: For each state, there are five possible actions: .
- : move upwards
- : move rightwards
- : move downwards
- : move leftwards
- : stay in the same location
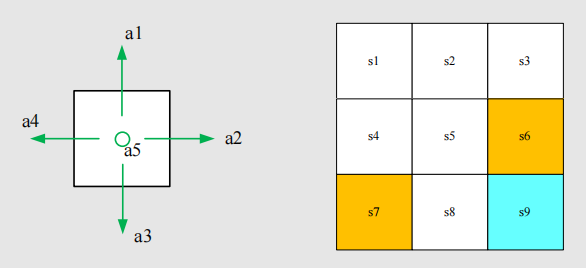
Action space: The set of all actions .
Question: Can different states have different sets of actions?
State transition
When taking an action, the agent may move from one state to another. Such a process is called state transition.
- At state , if we choose action , then what is the next state?
- At state , if we choose action , then what is the next state?
- State transition defines the interaction with the invironment.
- Question: Can we define the state transition in other ways?
- Yes
Forbidden area: At state , if we choose action , then what is the next state?
- Case1: the forbidden area is accessible but with penalty. Then,
- Case2: the forbiden area is inaccessible (e.g. surrounded by a wall).Then,
We consider the first case, which is more general and challenging.
Tabular representation: We can use a table to describe the state transition:
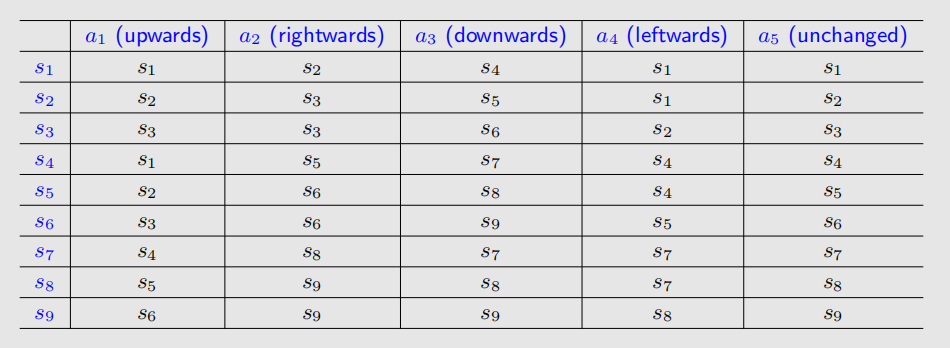
Can only represent deterministic cases.
State transition probability: Use probability to describe state transition!
- Intuition: At state , if we choose action , the next state is .
- Math:
Here it is a deterministic case. The state transition could be stochastic (for example, wind gust).
Policy
Policy tells the agent whay actions to take at a state.
Intuitive representation: The arrows demonstrate a policy.
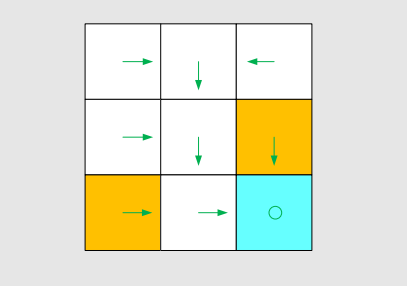
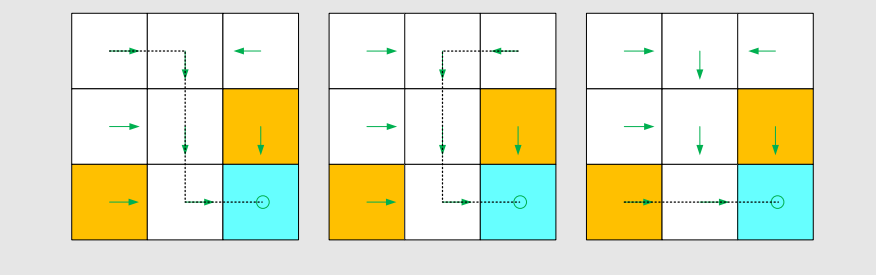
Based on this policy, we get the following paths with different starting points.
Mathmatical representation: using conditional probability
For example, for state :
It’s a deterministic policy.
There are stochastic policies.
For example:
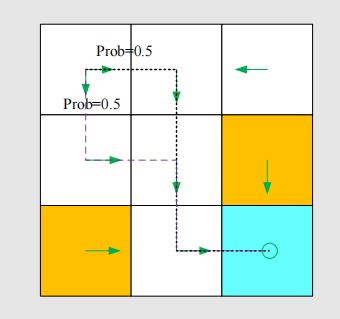
In this policy, for :
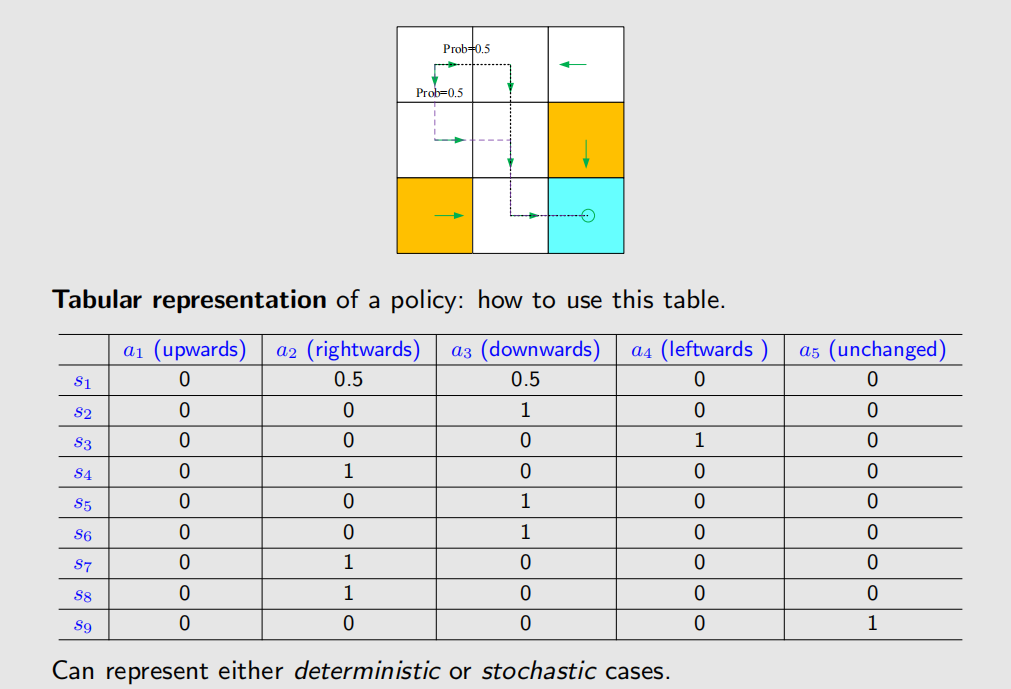
这种表格非常的 general,我们可以用它来描述任意的 policy。
在编程中如何实现概率表达呢,我们可以选取一个采样区间 [0,1]:
- if , take action ;
- if , take action ;
Reward
Reward is one of the most unique concepts of RL.
Reward: a real number we get after taking an action.
- A positive reward represents encouragement to take such actions.
- A negative reward represents punishment to take such actions.
Questins:
- What about a zero reward?
- No punishment.
- Can positive mean punishment?
- Yes.
In the grid-world example, the rewards are designed as follows:
- If the agent attemps to get out of boundary, let
- If the agent attemps to enter a forbidden cell, let
- If the agent reches the target cell, let
- Otherwise, the agent gets a reward of .
Reward can be interpreted as a human-machine interface, with which we can guide the agent to behave as what we expect.
For example, with the above designed rewards, the agent will try to avoid getting out of the boundary or stepping into the forbidden cells.
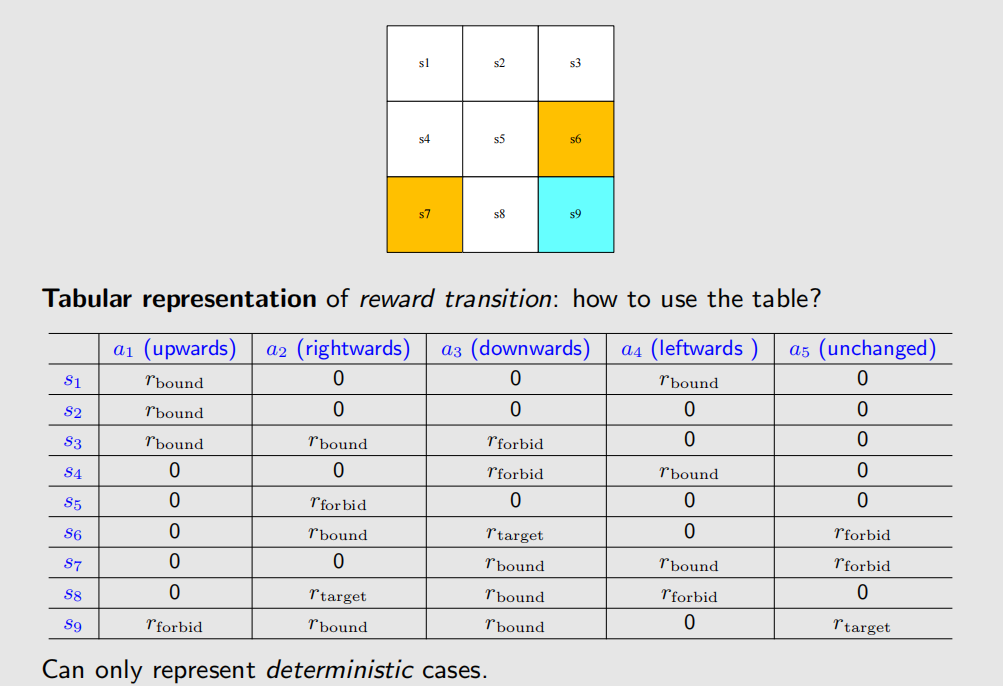
Mathematical description: conditional probability
- Intuition: At state , if we choose action , the reward is .
- Math: and
Remarks:
- Here it is a deterministic case. The reward transition could be stochastic.
- For example, if you study hard, you will get rewards. But how much is uncertain.
- The reward depends on the state and action, but not the next state (for example, consider and ).
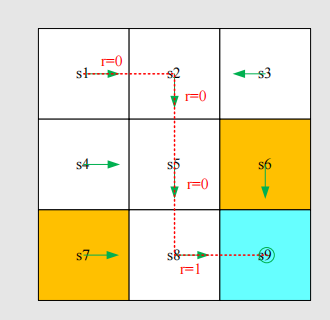
Trajectory and return
A trajectory is a state-action-reward chain:
The return of this trajectory is the sum of all the rewards collected along the trajectory:
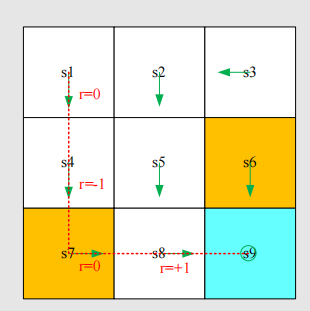
A different policy gives a different trajectory:
The return of this path is:
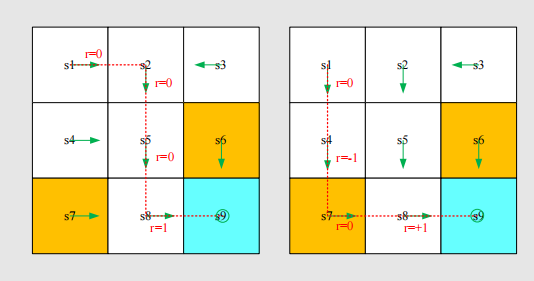
Which policy is better?
- Intuition: the first is better, because it avoids the forbidden areas.
- Mathematics: the first one is better, since it has a greater return!
- Return could be used to evaluate whether a policy is good or not (see details in the next lecture)!
Discounted return
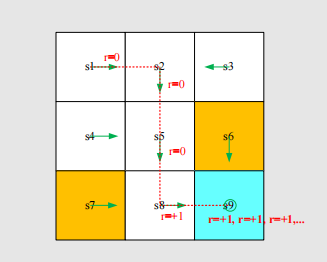
A trajectory may be infinite:
The return is
The definition is invalid since the return diverges!
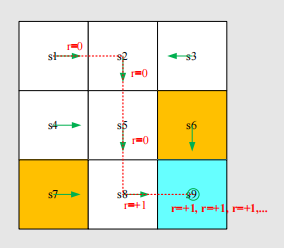
Need to introduce a discount rate
Discounted return:
Roles:
- The sum becomes finite.
- Balance the far and near future rewards.
Explanation:
- If is close to 0, the value of the discounted return is dominated by the rewards obtained in the near future.
- If is close to 1, the value of the discounted return is dominated by the rewards obtained in the far future.
- 简而言之,如果 比较小,那 discounted return 比较近视;如果 比较大,那 discounted return 比较远视。
Episode
强化学习(Reinforcement Learning)中,episode 是一个核心概念,指的是智能体(agent)与环境(environment)交互的完整序列,从初始状态开始,到终止状态(terminal state)结束,期间不会被打断。
序列构成:一个 episode 由 状态(state)→ 行动(action)→ 奖励(reward)→ 下一状态(next state) 的循环组成,直到触发终止条件(例如游戏结束、任务完成等)
When interacting with the environment following a policy, the agent may stop at some terminal state. The resulting trajectory is called an episode (or a trial).
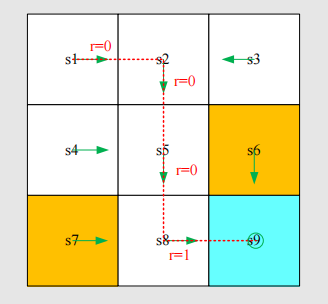
Example: episode
An episode is usually assumed to be a finite trajectory. Tasks with episodes are called episodic tasks.
Some tasks may have no terminal states, meaning the interaction with the environment will never end. Such tasks are called continuing tasks.
In the grid-world example, should we stop after arriving the target?
In fact, we can treat episodic and continuing tasks in a unified mathematical way by converting episodic tasks to continuing tasks.
- Option 1: Treat the target state as a special absorbing state. Once the agent reaches an absorbing state, it will never leave. The consequent rewards .
- Option 2: Treat the target state as a normal state with a policy. The agent can still leave the target state and gain when entering the target state.
We consider option 2 in this course so that we don’t need to distinguish the target state from the others and can treat it as a normal state.
Markov decision process (MDP)
Key elements of MDP:
- Sets:
- State: the set of states .
- Action: the set of actions is associated for state .
- Reward: the set of rewards .
- Probability distribution:
- State transition probability: at state , taking action , the probability to transit to state is
- Reward probability: at state , taking action , the probability to get reward is
- Policy: at state , the probability to choose action is
- Markov property: memoryless property
All the concepts introduced in this lecture can be put in the framework in MDP.
The grid world could be abstracted as a more general model, Markov process.
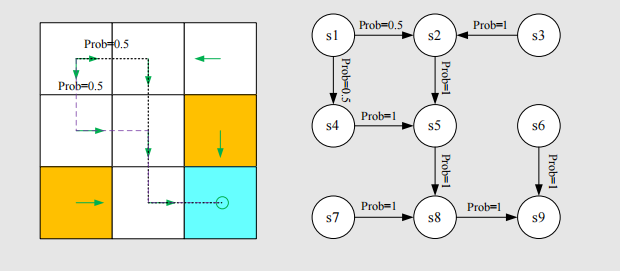
The circle represent states and the links with arrows represent the state transition.
Markov decision process becomes Markov process once the policy is given.
MDP VS MP
马尔科夫过程(Markov Process, MP)和马尔科夫决策过程(Markov Decision Process, MDP)是强化学习中的两个核心概念,它们之间存在重要的区别:
马尔科夫过程 (Markov Process, MP)
马尔科夫过程是一个二元组 ,其中:
- 是状态空间
- 是状态转移概率矩阵
特点:
- 被动性:系统状态的转移是自动发生的,没有外部决策者的干预
- 随机性:状态转移完全由概率决定
- 马尔科夫性:下一个状态只依赖于当前状态,与历史无关
数学表达:
马尔科夫决策过程 (Markov Decision Process, MDP)
马尔科夫决策过程是一个四元组 ,其中:
- 是状态空间
- 是动作空间
- 是状态转移概率矩阵(依赖于动作)
- 是奖励函数
特点:
- 主动性:存在决策者(智能体)可以选择动作
- 目标导向:通过奖励机制引导决策
- 策略依赖:状态转移依赖于所选择的动作
数学表达:
主要区别对比
| 特征 | 马尔科夫过程 (MP) | 马尔科夫决策过程 (MDP) |
|---|---|---|
| 决策能力 | 无决策者,被动观察 | 有智能体主动决策 |
| 动作空间 | 无动作概念 | 有明确的动作空间 |
| 状态转移 | ||
| 奖励机制 | 无奖励 | 有奖励函数 |
| 优化目标 | 无优化目标 | 最大化累积奖励 |
| 应用场景 | 系统建模、概率分析 | 强化学习、决策优化 |
关系总结
- MP是MDP的特殊情况:当MDP中只有一个动作可选时,MDP退化为MP
- MDP扩展了MP:在MP基础上增加了动作选择和奖励机制
- 从描述到控制:MP描述系统行为,MDP控制系统行为
Summary
By using grid-world examples, we demonstrated the following key concepts:
- State
- Action
- State transition, state transition probability
- Reward, reward probability
- Trajectory, episode, return, discounted return
- Markov decision process















